2018年,是中國人工智能產業從技術探索邁向規模化應用的關鍵一年。在這一背景下,《中國人工智能開源軟件發展白皮書(2018)》的發布,為我們系統梳理了AI基礎軟件,特別是開源生態的發展脈絡、核心挑戰與未來機遇,其配套解讀PPT則提綱挈領地呈現了關鍵洞察。
一、白皮書核心洞察:開源已成為AI創新的核心引擎
白皮書明確指出,開源模式正在深刻重塑人工智能的技術研發與產業落地路徑。在基礎軟件層面,這主要體現在:
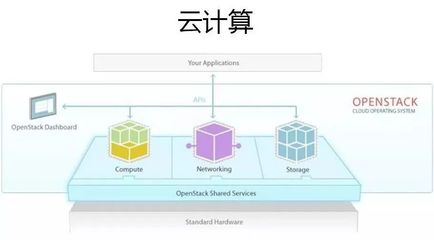
- 框架與平臺的開源化主流趨勢:以百度PaddlePaddle、騰訊Angel、小米MACE等為代表的國產深度學習框架紛紛開源,與國際主流框架TensorFlow、PyTorch形成協同與互補的生態格局。開源框架降低了AI技術研發門檻,加速了算法模型的迭代與共享。
- 從“模型開源”到“全棧開源”的演進:早期開源主要集中在算法模型層面。2018年,趨勢已擴展至更底層的數據處理、訓練部署、推理優化乃至硬件適配的全棧工具鏈。這促進了從芯片、框架到應用的整體協同優化。
- 共同體協作模式興起:AI開源不再是單點項目的發布,而是圍繞核心項目形成的“共同體”。企業、高校、科研機構及個人開發者基于開源項目協作,共同解決從基礎算力、大規模數據處理到模型安全可信等復雜問題。
- 標準化與生態建設的迫切性:隨著開源項目激增,框架接口、模型格式、部署標準不統一的問題凸顯,成為制約產業效率的瓶頸。白皮書呼吁加強開源治理,推動接口標準化和生態互聯互通。
二、人工智能基礎軟件開發的關鍵挑戰
配套解讀材料重點剖析了基礎軟件開發面臨的“硬骨頭”:
- 性能與易用性的平衡:如何讓基礎軟件既能在超大規模數據集和復雜模型上保持極致性能(支持分布式訓練、混合精度計算等),又能讓廣大應用開發者便捷使用,是框架設計的關鍵。
- 面向場景的優化與部署:AI模型從實驗室到工廠、手機、IoT設備的部署(即“推理”環節)面臨巨大挑戰。基礎軟件需提供輕量化、低功耗、跨平臺的推理引擎,并解決模型壓縮、編譯優化等難題。
- 系統安全與數據隱私:開源軟件的供應鏈安全、模型對抗攻擊的魯棒性、聯邦學習等隱私計算技術與開源生態的融合,成為基礎軟件必須內置的核心能力。
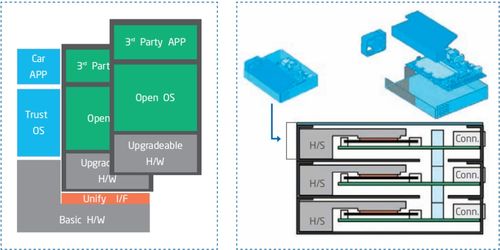
- 與異構硬件的協同:面對GPU、NPU、FPGA等多樣化的AI加速芯片,基礎軟件需要具備強大的硬件抽象和適配能力,實現“一次開發,多處部署”,降低軟硬件耦合度。
三、展望與建議:構建健康可持續的開源生態
白皮書及解讀為未來AI基礎軟件的發展指明了方向:
- 強化核心基礎能力:鼓勵在自動機器學習(AutoML)、強化學習、可解釋AI等前沿方向的底層開源工具研發,夯實長期創新基礎。
- 推動產-學-研-用閉環:通過開源項目,將產業界的真實需求、學術界的前沿突破、研發團隊的工具創新和最終用戶的反饋緊密連接,加速技術落地。
- 積極參與國際治理:在開源許可證、技術標準、安全規范等方面積極發聲,推動形成包容、公平、透明的國際開源治理規則,保障我國技術的可持續發展與安全。
- 重視人才培養與開源文化:開源不僅是代碼共享,更是知識共享和協同文化。需大力培育既懂AI技術又具備開源協作精神的復合型人才。
###
《中國人工智能開源軟件發展白皮書(2018)》及其解讀,不僅是一份階段性的,更是一份面向未來的行動指南。它揭示了一個核心共識:在人工智能時代,基礎軟件,尤其是開源的基礎軟件,是技術民主化和產業智能化的基石。通過共建共享、開放協作的開源生態,中國人工智能產業有望在核心基礎層構建起自主可控且富有活力的創新體系,為全球AI發展貢獻獨特力量。