在當今快速發展的數字時代,云計算、大數據和人工智能已成為推動社會進步和技術創新的核心力量。它們各自扮演著獨特的角色,同時又緊密交織,共同構成了現代信息技術的基礎架構。本文將詳細闡述這三者的基本概念、相互關系,并特別聚焦于人工智能基礎軟件開發在這一生態系統中的關鍵地位。
一、 基本概念解析
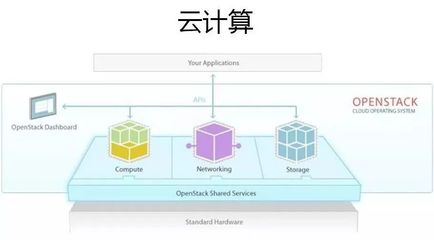
- 云計算:云計算是一種通過互聯網按需提供計算資源(如服務器、存儲、數據庫、網絡、軟件)的服務模式。其核心特征是按需自助服務、廣泛的網絡訪問、資源池化、快速彈性伸縮和可度量的服務。它類似于從傳統自建電廠發電轉向從電網按需購電,極大地降低了企業和個人的IT門檻與成本。主要服務模式包括基礎設施即服務(IaaS)、平臺即服務(PaaS)和軟件即服務(SaaS)。
- 大數據:大數據指的是無法在合理時間內用傳統軟件工具進行捕捉、管理和處理的巨量、高增長率及多樣化的信息資產。其特點通常概括為“5V”:大量(Volume)、高速(Velocity)、多樣(Variety)、低價值密度(Value)和真實性(Veracity)。大數據技術旨在從這些海量、復雜的數據集中提取有價值的信息和洞見。
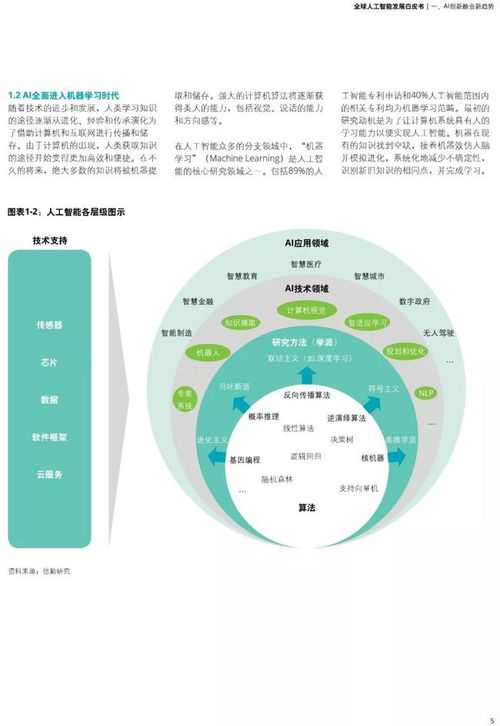
- 人工智能:人工智能是研究、開發用于模擬、延伸和擴展人的智能的理論、方法、技術及應用系統的一門新的技術科學。其目標是讓機器能夠像人一樣思考、學習、推理和解決問題。當前主流方向包括機器學習(尤其是深度學習)、自然語言處理、計算機視覺和專家系統等。
二、 三者的相互關系:一個協同增效的生態系統
云計算、大數據和人工智能并非孤立存在,而是形成了一個相互依存、正向循環的緊密生態。
- 云計算為大數據和AI提供基石:
- 計算與存儲平臺:處理海量數據和訓練復雜的AI模型需要巨大的計算能力(如GPU集群)和存儲空間。云計算的彈性伸縮和資源池化特性,使得企業和研究機構能夠以可承受的成本、按需獲取這些資源,無需巨額前期硬件投資。例如,訓練一個大型深度學習模型可以在云端快速調配數百個GPU實例,完成后立即釋放。
- 服務化與工具集成:主流云平臺(如AWS, Azure, GCP, 阿里云)都提供了豐富的大數據服務(如Hadoop/Spark托管服務、數據倉庫)和AI服務(如機器學習平臺、預訓練模型API),將復雜的技術棧封裝成易用的服務,極大地加速了應用開發。
- 大數據為AI提供“燃料”與“訓練場”:
- 數據源泉:AI,特別是機器學習模型的性能,高度依賴于數據的規模和質量。大數據技術負責收集、清洗、存儲和管理來自各種來源(物聯網、社交媒體、交易記錄等)的海量數據,為AI模型提供了必需的訓練“食糧”。沒有大數據,AI將成為“無米之炊”。
- 應用場景與驗證:大數據分析中發現的復雜模式、關聯和預測需求,恰恰是AI擅長解決的問題。大數據的處理結果也為AI模型的優化和效果評估提供了依據。
- AI為大數據和云計算注入“智能”與價值:
- 提升大數據處理能力:傳統大數據分析多依賴于預先定義的規則和查詢。AI(尤其是機器學習)能夠自動從數據中發現深層次、非線性的模式和洞見,實現智能化的數據分析、預測和決策支持,將數據價值最大化。例如,用AI進行實時欺詐檢測或精準推薦。
- 優化云計算本身:AI技術被用于智能管理云資源,實現更高效的負載均衡、能耗管理、故障預測和自動化運維,讓云平臺自身變得更“聰明”。
三、 聚焦:人工智能基礎軟件開發
在三位一體的生態中,人工智能基礎軟件開發是具體實現AI能力的關鍵環節。它指的是構建支持AI模型研發、訓練、部署和管理的底層軟件框架、工具庫、開發平臺和系統。
- 核心組成部分:
- 深度學習框架:如TensorFlow, PyTorch, JAX,它們提供了構建和訓練神經網絡的底層抽象和計算圖,是AI開發者的“主力工具”。
- 機器學習平臺/庫:如Scikit-learn, XGBoost,用于傳統機器學習算法。以及MLflow, Kubeflow等用于管理機器學習生命周期的平臺。
- 計算加速庫:如CUDA, cuDNN (針對NVIDIA GPU),以及針對其他硬件的優化庫,用于極大提升模型訓練和推理速度。
- 模型部署與服務化工具:如TensorFlow Serving, TorchServe, Triton Inference Server,負責將訓練好的模型高效、穩定地部署到生產環境(通常是云上),并提供API服務。
- 數據管理與處理工具:與大數據棧集成,用于高效準備訓練數據。
- 與云計算和大數據的整合實踐:
- 云原生AI開發:現代AI基礎軟件日益云原生化。開發者可以在云上直接使用托管的Jupyter Notebook環境,調用云存儲中的大數據,利用云上的彈性GPU資源,通過云平臺提供的機器學習服務(如Amazon SageMaker, Google Vertex AI, Azure Machine Learning)來完成從數據準備、模型訓練、調優到部署的全流程,實現DevOps for ML (MLOps)。
- 大數據管道與AI管道融合:數據流水線(使用Apache Airflow, Spark等)與模型訓練流水線無縫銜接。實時數據流(如Kafka)可以直接作為AI模型的在線推理輸入。
- 開源與云服務的結合:開發者既可以使用開源的AI框架(如PyTorch)在云虛擬機上自主控制一切,也可以直接使用云廠商提供的、基于這些開源框架構建的、更高級別的托管服務,在效率與控制力之間做出權衡。
結論
云計算、大數據和人工智能共同構成了一個強大的技術飛輪:云計算提供彈性的“算力工廠”和“工具箱”,大數據提供豐富的“原材料礦藏”,而人工智能則是將原材料在算力工廠中加工成高價值“智能產品”的尖端工藝。 人工智能基礎軟件開發,正是設計和優化這套“工藝”及“生產線”的核心工程活動。隨著三者融合的不斷深入,我們正加速邁向一個更加智能、高效和以數據驅動的未來。對于開發者和企業而言,理解并善用這三者的協同關系,是贏得數字化競爭的關鍵。